





Improving Platform Resiliency - Error Handling Approaches for Kafka-based Systems
- Technology
- 16 July 21




Introduction
Kafka is an open-source real-time streaming messaging system built around the publish-subscribe system. In a service-oriented architecture, instead of subsystems establishing direct connections with each other, the producer subsystem communicates information via a distributed server, which brokers information and helps move enormous number of messages with low-latency and fault tolerance and allows one or more consumers to concurrently consume these messages.
Kafka does an excellent job with respect to fault-tolerance and ensuring that the messages that are delivered are not lost by partitioning, replication, and distributing the data across multiple brokers.
In distributed systems failures are inevitable, whether it be DB connection failure, or network call failure, or outages in downstream dependencies, especially in a microservices ecosystem.
Failure in Consumers
There are multiple issues that could occur on the consumer side that need special handling. When implementing the Kafka Consumer, there are some scenarios that need to be considered that need special handling:
Downstream Service or Data Store Failure
Consumer is not able to process the message because a downstream microservice API is unavailable or returns an error, or a DB it's trying to connect to is down or unresponsive.
This blog post discusses some of the error handling mechanisms that we implemented as a part of the MetricStream Platform to improve the robustness and resiliency of the Platform.
Data Format Changes or Event Version Incompatibility
The consumer is expecting the message payload to be in a certain format, whereas the producer has changed the format of the message e.g., a required field is removed, i.e., for example the consumer is unable to deserialize the message which is sent by the producer in a certain format.
Producer Failures
Unable to reach Kafka cluster
The producer may fail to push message to a topic due to a network partition or unavailability of the Kafka cluster, in such cases there are high chances of messages being lost, hence we need a retry mechanism to avoid loss of data. So, the approach we take here is to store the message in a temporary secondary store DB/Cache and retry the messages from the secondary store and try to write the message to the main topic.
Problem with Simple Retries
Clogged processing
When we are required to process many messages in real time, repeatedly failed messages can clog processing. The worst offenders consistently exceed the retry limit, which also means that they take the longest and use the most resources. Without a success response, the Kafka consumer will not commit a new offset and the batches with these bad messages would be blocked, as they are re-consumed again and again.
Difficulty retrieving retry metadata
It can be cumbersome to obtain metadata on the retries, such as timestamps and nth retry. If requests continue to fail retry after retrying, we want to collect these failures in a DLQ for visibility and diagnosis. A DLQ should allow listing for viewing the contents of the queue, purging for clearing those contents, and merging for reprocessing the dead-lettered messages, allowing comprehensive resolution for all failures affected by a shared issue.
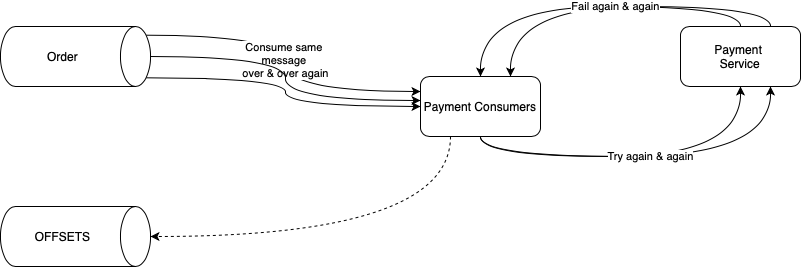
Processing Retry Records in Separate Topics
To address the problem of blocked batches, we set up a distinct retry queue using a separately defined Kafka topic. Under this paradigm, when a consumer handler returns a failed response for a given message after a certain number of retries, the consumer publishes that message to its corresponding retry topic. The handler then returns true to the original consumer, which commits its offset.
Error Handling on The Producer Side
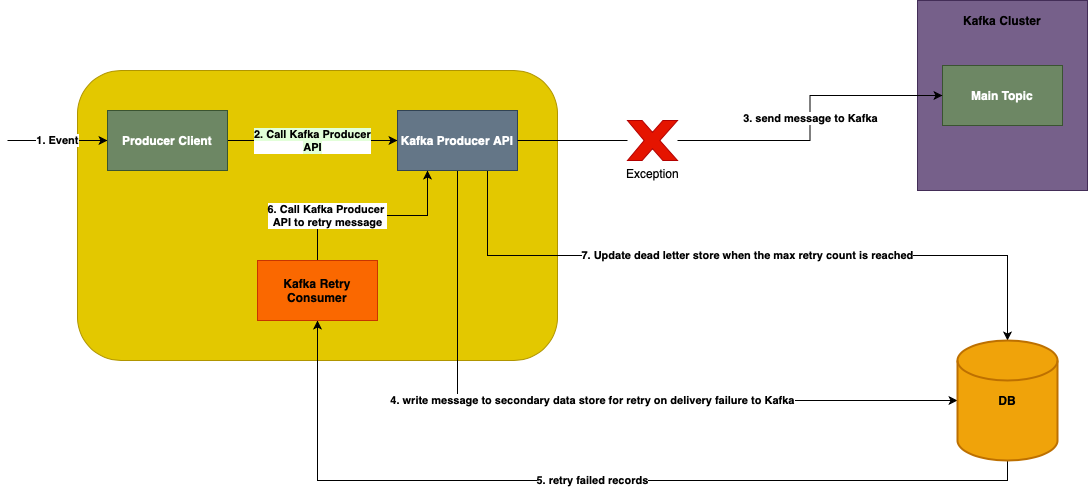
Here are some of the possible scenarios why the Producer API is unable to send the message.
- Kafka cluster itself is down and unavailable.
- If Kafka producer configuration “acks” is configured to “all” and some brokers are unavailable.
- If Kafka producer configuration “min.insyn.replicas” is specified as 2 and only one broker is available. Here min.insync.replicas and acks allow you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of “all”. This will ensure that the producer raises an exception if many replicas do not receive a write.
Detailed Explanation of Producer Retry Mechanism
The approach to recover from the above errors involves building a retry mechanism within the producer to ensure that there is an auto-retry process to try and re-deliver messages and a dead-letter store to save messages that were undeliverable even after the auto-retry process.
The steps involved are (see diagram above):
1. Client invokes the Kafka client's producer API to push a message to the main topic (configured in the producer API).
2. If there is an exception thrown by Kafka while pushing the message to the topic, then we need a way of handling the error and managing the message in way that we don't lose the message (prevent data loss).
3. When there is an exception returned by Kafka, then the message will be written to a secondary store.
4. Retry policy defines three key things,
- Number of retries: This will be a positive integer value which defines how many times the handler will try to send the message to the main topic. If the number of attempted retries exceeds this value, the message will be pushed to the dead letter store, which will have to be then manually processed by adding a consumer by the developer.
- Back-off period: This defines the delay between each retry, this can be a fixed delay or variable delay which grows after every retry. This is important to slow down the rate of error processing, such that we don't spend too many resources in error processing and other healthy messages can be processed as well, instead of just doing error processing.
- Recovery callback: If developer wants to implement some additional logic for recovery or push the message to some persistent store or just log the error messages, then he/she can provide a recovery callback which will be called when all the retries are exhausted
5. Based on the retry policy the message will be pushed to a secondary store (DB) till the max retry limit is not reached, once the max retry count is reached, the message will be pushed to the dead letter store.
6. The retry consumer implemented internally as part of the framework will read the messages from the retry store and invoke the producer API to push the message to the main topic.
7. The retry will be done by a separate set of threads from a dedicated retry thread pool, which will not interfere with the main threads pushing the data to Kafka topic or consuming data from Kafka topics.
8. The error handling is controlled through a flag, which the producer can set at the API level, as certain messages may not be as important as the others, such that we can allow the messages from being lost, e.g., log messages.
9. There will be a flag "enableRetry" which will be enabled by default; this can be set at the producer API level to enable/disable error handling.
Error Handling on The Consumer Side
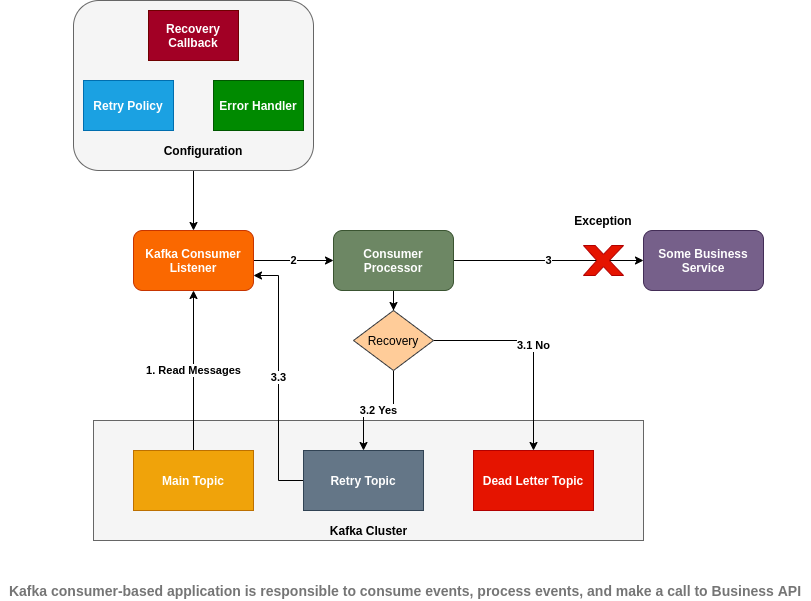
Some of the scenarios where the consumer process could run into errors are:
- Errors may occur in the consumer while processing the record received from the topic this consumer is listening on. Exceptions could be of any type e.g., IO Exception due to DB connectivity failure or error writing to a file.
- The error handling/retry mechanism provided in the diagram above will prevent every consumer from implementing their own business logic for handling errors and will provide a standard retry mechanism for every consumer extending from the framework.
To handle these errors, the following mechanisms can be followed to improve resiliency:
Following are a series of steps to be followed for retrying in case of a failure on the consumer end as shown in the above figure:
1. Kafka consumer listener in Service A tries to consume an event/message from the main topic.
2. The consumer in Service A has a dependency on another service e.g., Service B or a data store to complete the processing, e.g., it may try to invoke another API on a microservice to fetch or update some data.
3. There is an exception thrown while making a call to the microservice i.e., Service B due to some network failure or the service throws an exception due to some internal service failure (i.e., Internal Server Error or Service not available)
- 3.1. If the retry consumer is unable to process the event after repeated retries and reaches the max retries, then it will push the event to the dead letter topic.
- 3.2. If retry is enabled, then on exception, the event is pushed to a retry topic.
- 3.3. Retry consumer will consume the event from the retry topic and try to re-process the event with some delay.
Detailed Explanation of the Consumer Retry Mechanism
- The consumer can fail while processing an invalid record or due to some runtime error, which could occur due to a failed connection to DB or failed network call to another microservice.
- The framework mentioned in the above diagram provides a configurable way for error handling and retry mechanism, such that the consumers don't have to do explicit do the error handling.
- The consumer will be able to configure the exception or set of exceptions for which it wants to retry the message delivery.
- The consumer can configure the retry policy i.e., the number of times the message processing should be retried, along with back-off period, which will add a delay to every retry of fixed or variable interval based on the configuration.
- When there is an exception in the consumer service, the Kafka consumer handler will trigger a call to retry the message delivery in a separate retry thread, which is part of a separate thread pool, not interfering with the main thread pool.
- The retry thread will try sending the message by invoking the producer API at certain intervals based on the retry policy.
- It is important not to simply re-attempt failed requests immediately one after the other; doing so will amplify the number of calls, spamming bad requests. Rather, each subsequent level of retry consumers can enforce a processing delay, in other words, a timeout that increases as a message steps down through each retry topic.
- The delay/backoff is added while consuming the message from the retry topic, the consumer will delay processing of the message from the topic, hence the records are still part of the retry topic and not loaded in memory once the delay time interval elapses consumer will read the message from the topic and invoke the producer API.
- Once the total number of allowed retries are exhausted, the message will be pushed to the dead letter topic.
- The state of the count is maintained in the message itself i.e., part of the message header, for every retry the count is updated in the header of the message, that is how we can know the exact retry count, similarly backoff period can also be maintained in the message header to track the backoff period of each event in case of backoff strategy like exponential backoffs wherein the backoff increases with every retry etc.
- The retry handler will not try to send the message again post the number of retries are exhausted.
- It may optionally implement circuit breaker as well i.e., if the consumer is failing for an extended period, then it can kill the main thread consuming from the main topic.
- Optionally, we may provide a recovery call-back handler to allow the developer to implement any specific business logic for error handling e.g., storing the errors to the DB or logging the errors.
- The approach of separating out the main consumer & retry thread is designed to not block the main consumer thread and allow it process the regular valid events, otherwise the main thread will be spending time doing retry processing, which will prevent the other valid messages from being processed till the time retry is completed, there are chances that some event may be erroneous and may fail for all retries, this will starve the main consumer threads whose job is to process the valid events, hence the retry mechanism is designed to push the invalid/failed event to another topic i.e. retry topic and a separate retry consumer thread is created whose job is to just process the failed events and does not starve the main thread, hence both the main thread and retry thread can run parallelly and process records without starving each other.
Dead Letter Queue/Topic
- If a consumer of the retry topic still does not return success after completing the configured number of retries, then it will publish that message to the dead letter topic.
- From there, several techniques that can be employed for listing, purging, and merging from the topic, such as creating a command-line tool backed by its own consumer that uses offset tracking.
- Dead letter messages are merged to re-enter processing by being published back into the first retry topic. This way, they remain separate from, and are unable to impede, live traffic.
Simple Flow Diagram: Explaining Consumer Retry Mechanism
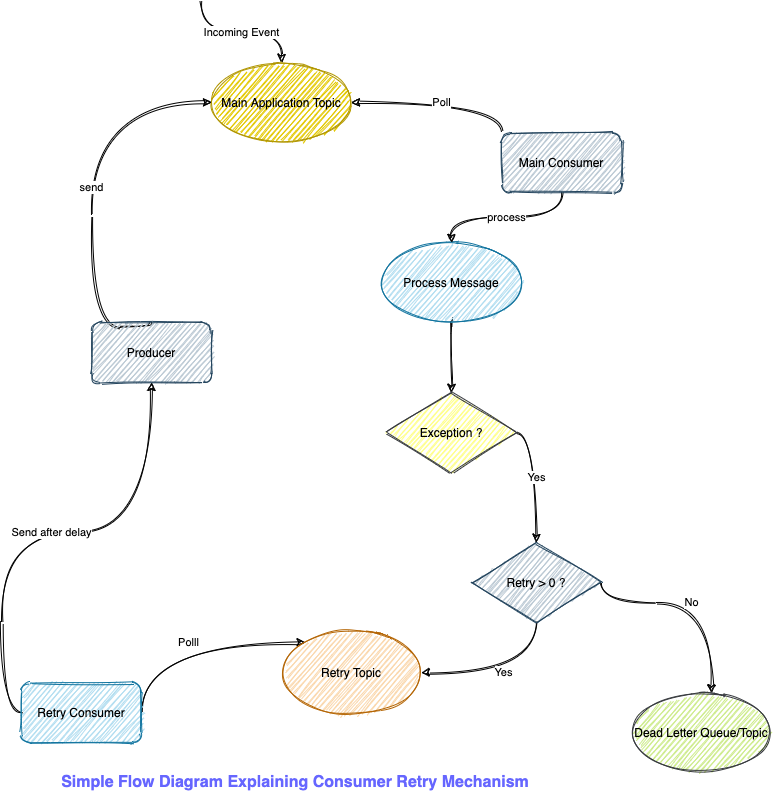
Additional Considerations
Naming Convention for topics
Valid Characters for Kafka topics:
- ASCII alphanumeric, ‘.’, ‘_’, and ‘-‘ (a-z, A-Z, 0-9, . (dot), _ (underscore), and - (dash))
Max Allowed Topic Name Length:
- The topic name can be up to 255 characters in length
Main topics convention:
<namespace/organisation prefix>.<product/module/package>.<event-type> <namespace/organisation prefix>.<product/module/package>.<data-type>.<event-type>
Example: Topic Naming Convention for Orders Created, following is how the topic name is constructed.
- Namespace/Organisation Prefix – org
- Product – orders
- Event type – created
Resulting Topic Name: org.orders.created
Retry Policy Parameters
- Back-off period (in milliseconds, represents the fixed delay between each retry) - Default: 3000 ms
- Retry Count (Numeric value, represent the number of times a message should be retried before being exhausted, once exhausted it should be moved to dead letter topic) - Default: 3
Example of retry policy configuration in KafkaListener annotation:
@KafkaListener(name = "workflow", topics = "forms", group = "workflow", retryPolicy = @SimpleRetryPolicy(retryBackoffMs = 5000, retryCount = 2, exceptions = {KafkaConsumerException.class, IOException.class}))
Other considerations (other retry policy types)
Following mechanisms can be optionally added to the producer/consumer retry policy.
- Circuit Breaker Retry Policy: Trips circuit open after a given number of failures and stays open until a set timeout elapses.
- Exponential Backoff Policy: Increases back off period exponentially. The initial interval and multiplier are configurable.


